If you’ve ever run a Linux system in production or even just kept a personal server, you’ll know that running out of disk space is one of the most frustrating issues. Suddenly, your applications stop working, databases won’t write new data, and log files keep filling up like a runaway train.
The good news is that Linux makes it surprisingly easy to monitor disk usage and catch problems before they happen. All you need is a small shell script, a bit of logic, and maybe an email alert (or a message to your Slack channel, if you’re fancy).
In this article, we’ll build a simple script that checks your disk usage and sends an alert if it goes over 80%.
Step 1: Check Disk Usage on Linux
Before writing a script, you need to know your current disk space usage on your system using the df command.
df -h
The -h flag means “human-readable”, so instead of showing raw blocks of data, it formats the output in GB and MB, which is much easier to understand.
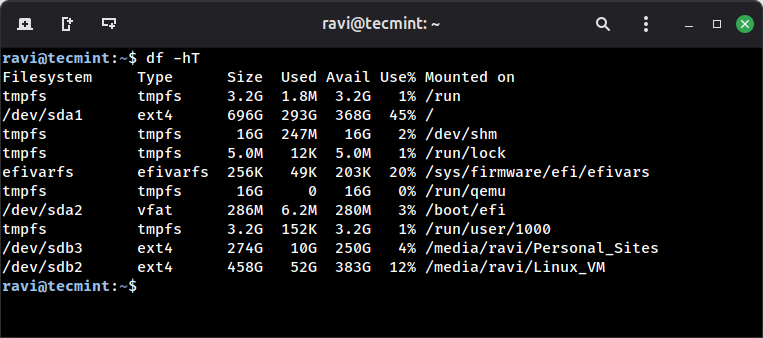
In the example above, the root partition / (/dev/sda1) is sitting at 45%, which is perfectly healthy, but once it starts climbing past 80%, that’s our red flag; it means space is running out.
Step 2: Create a Script to Monitor Disk Usage
Now that you know how to check disk usage manually, let’s turn it into something automatic using a shell script, which are great for such things because they let us take commands we normally run and tie them together with a little bit of logic.
Here’s a very simple script to monitor your root (/) partition:
#!/bin/bash
# Set threshold (percentage)
THRESHOLD=80
# Extract the usage percentage for root filesystem
USAGE=$(df -h / | awk 'NR==2 {print $5}' | sed 's/%//')
# Compare usage against threshold
if [ "$USAGE" -ge "$THRESHOLD" ]; then
echo "Warning: Disk usage is at ${USAGE}% on $(hostname)" | mail -s "Disk Alert: $(hostname)" [email protected]
fi
Let’s break down what’s happening here:
THRESHOLD=80→ This is the limit we care about, anything higher is too risky.df -h /→ This checks the root filesystem only.awk 'NR==2 {print $5}'→ From the df output, this grabs the “Use%” column.sed 's/%//'→ Strips off the%sign so we can treat it as a number.- The
ifblock → If the disk usage goes above the threshold, it triggers an alert.
Right now, the script sends an email using the mail command. If you haven’t set up email on your system, don’t worry, I’ll show you how to set it up.
Step 3: Monitor All Partitions Disk Usage
Most servers don’t rely on a single partition; instead, they’re typically split into several, such as /, /home, /var, or even /data. If you only keep an eye on the root (/) partition, you risk missing critical issues elsewhere, for example, if /var fills up with logs, your applications could fail even though / still has plenty of space.
Here’s a slightly improved version that checks all mounted filesystems:
#!/bin/bash
THRESHOLD=80
# Loop through each filesystem listed by df
df -h | grep '^/dev/' | while read line; do
USAGE=$(echo $line | awk '{print $5}' | sed 's/%//')
PART=$(echo $line | awk '{print $6}')
if [ "$USAGE" -ge "$THRESHOLD" ]; then
echo "Warning: Partition $PART is at ${USAGE}% on $(hostname)" | mail -s "Disk Alert: $(hostname)" [email protected]
fi
done
Now, instead of checking just /, it runs through every filesystem under /dev/ and if any partition crosses 80%, you’ll get a warning email.
Step 4: Automating the Script with Cron
Cron is a simple scheduling service on Linux that can run commands at fixed times or intervals. You can use it to make your disk monitoring script run automatically, say, every hour.
To set it up, open your crontab with:
crontab -e
Add this line at the bottom:
0 * * * * /path/to/disk_check.sh
This means:
0→ run at the start of the hour.* * * *→ every hour, every day./path/to/disk_check.sh→ replace this with the actual location of your script.
Save and exit, and cron will take care of the rest. From now on, your script will quietly check disk usage in the background and alert you if things look bad.
Step 5: Testing the Script
Before you rely on this script, it’s smart to test it. After all, you don’t want to wait until your disk is actually 80% full to find out if your alert system works.
The easiest way to test is by temporarily lowering the threshold:
THRESHOLD=1
That way, the script will almost certainly trigger an alert right away since most partitions are at least 1% full. Once you confirm that emails or logs are working, change it back to 80.
If you’re not ready to configure email, you can replace the mail command with something simpler, like:
echo "Warning: Partition $PART is at ${USAGE}% on $(hostname)"
This will just print the alert to your terminal, which is useful for quick debugging.
Step 6: Setting Up Email Notifications
Our script uses the mail command to send alerts, but this tool isn’t always available by default. You’ll need to install it first:
sudo apt install mailutils [On Debian] sudo yum install mailx [On RHEL]
Once installed, you should make sure your server can actually send emails, which may require some extra setup, like configuring Postfix, Gmail SMTP, or a third-party service such as SendGrid.
If you don’t want to deal with email right now, you can still make the script useful by logging alerts to a file:
echo "Disk usage alert: $PART at $USAGE%" >> /var/log/disk_alert.log
That way, you can check the log later or use the following command to watch alerts in real time.
tail -f /var/log/disk_alert.log
Step 7: When to Go Beyond Shell Scripts
Shell scripts are great for learning and are often enough for a single server or small project, but if you’re running multiple servers or need more detailed monitoring, you’ll probably want to move to dedicated monitoring tools.
- Nagios → One of the oldest and most reliable monitoring systems.
- Zabbix → Good if you want dashboards, graphs, and a central place to monitor many servers.
- Prometheus + Grafana → A modern setup where Prometheus collects metrics, and Grafana makes beautiful dashboards to visualize them.
Wrapping Up
With just a few lines of shell scripting, you’ve created a lightweight disk monitoring system that keeps an eye on your partitions and warns you before things get critical.
By setting a threshold, adding a bit of logic, and scheduling it with cron, you’ve automated a task that would otherwise require constant manual checks, which means fewer surprises, fewer outages, and more peace of mind.
If you want to take your Linux automation further, check out our related guide: How to Automate Daily Linux Health Checks with a Bash Script + Cron.