TL;DR
A) One fleet, one instance, stretched where justified
In VCF 9.0, identity is not a footnote. It is a design-time decision that changes:
The goal is predictable ownership and predictable blast radius.
Legend:
- SDDC Manager: 9.0.0.0 build 24703748
- vCenter: 9.0.0.0 build 24755230
- ESX: 9.0.0.0 build 24755229
- NSX: 9.0.0.0 build 24733065
- VCF Operations: 9.0.0.0 build 24695812
- VCF Operations fleet management: 9.0.0.0 build 24695816
- VCF Automation: 9.0.0.0 build 24701403
- VCF Identity Broker: 9.0.0.0 build 24695128
- VCF Installer: 9.0.1.0 build 24962180 (used to deploy the 9.0.0.0 component set)
Architecture Diagram
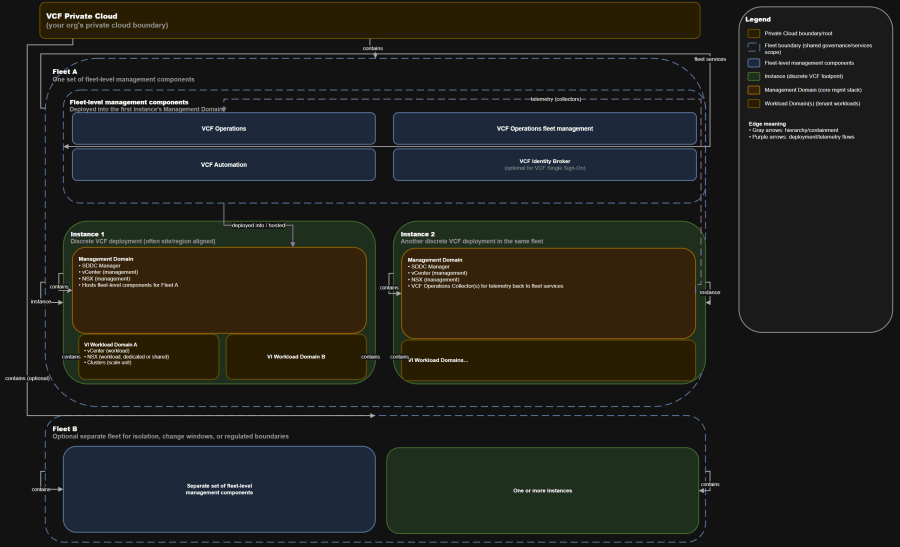
VCF private cloud -> VCF fleet -> VCF instance -> VCF domain -> vSphere clusters.
- Fleet-level management components centralize governance and shared services across a fleet.
- Instances retain discrete infrastructure management stacks (they do not merge into one giant vCenter/NSX).
- Domains are your lifecycle and isolation boundary for compute + storage + network resources.
Table of Contents
- Scenario
- Assumptions
- Scope and Code Levels
- The Ownership Model You Actually Need
- Day-0, Day-1, Day-2 Map
- Decision Criteria: Fleet vs Instance vs Domain vs Cluster
- Topology Posture
- Identity Boundaries and SSO Scope
- Failure Domain Analysis
- Operational Runbook Snapshot
- Anti-patterns
- Troubleshooting workflow
- Conclusion
Scenario
This article is pinned to the VCF 9.0 GA component set (versions and builds listed in TL;DR). If you are on a later 9.0.x maintenance release, terminology remains consistent, but exact UI placement and lifecycle sequencing can shift.
- Fleet-level services (VCF Operations, VCF Operations fleet management, VCF Automation, identity)
- Instance-level foundations (SDDC Manager and the instance management domain)
- Domain-level lifecycle and isolation (management domain and VI workload domains)
- Consumption teams (VMs, Kubernetes, platforms, and automation templates)
Scope and code levels referenced in this article (VCF 9.0 GA component set):
Assumptions
- You are deploying greenfield VCF 9.0.
- You are building at least one VCF private cloud containing one or more VCF fleets.
- You plan to deploy VCF Operations and VCF Automation early enough that the platform team uses them as the primary operational console for the environment.
- You will support three physical site configurations over time:
- Single site
- Two sites in one region
- Multi-region
Scope and Code Levels
This is the mental model that reduces panic during incidents.
Version Compatibility Matrix
| Layer | Component | Version | Build | Why you care operationally |
|---|---|---|---|---|
| Deployment | VCF Installer | 9.0.1.0 | 24962180 | The day-1 bring-up entrypoint for fleets and instances |
| Instance foundation | SDDC Manager | 9.0.0.0 | 24703748 | Drives instance lifecycle workflows and inventory control |
| Domain foundation | vCenter | 9.0.0.0 | 24755230 | Domain-level management boundary and API surface |
| Host layer | ESX | 9.0.0.0 | 24755229 | Your cluster capacity and patching blast radius unit |
| Network layer | NSX | 9.0.0.0 | 24733065 | Network segmentation, security policy, and edge services |
| Fleet services | VCF Operations | 9.0.0.0 | 24695812 | Central ops, visibility, grouping, and platform workflows |
| Fleet services | VCF Operations fleet management | 9.0.0.0 | 24695816 | Lifecycle for fleet services and related management components |
| Fleet services | VCF Automation | 9.0.0.0 | 24701403 | Self-service, governance, and policy-driven provisioning |
| Identity | VCF Identity Broker | 9.0.0.0 | 24695128 | Enables VCF Single Sign-On models and SSO scope decisions |
The Ownership Model You Actually Need
You are aligning architects, operations, and leadership on what VCF 9.0 is actually managing, and how responsibilities split across:
- Fleet boundary -> governance and shared services
- Instance boundary -> discrete infrastructure footprint and operational control plane
- Domain boundary -> lifecycle, isolation, and workload placement
- Cluster boundary -> scale unit and maintenance blast radius
“Who owns what” chart
These are starting targets that many teams use to set expectations. Tune them to your recovery strategy and staffing model.
| Construct or capability | Primary owner | Secondary owner | Day-2 responsibilities that must be explicit |
|---|---|---|---|
| VCF private cloud (org boundary) | Platform team | Security/GRC | Portfolio decisions, fleet count, policy and compliance guardrails |
| VCF fleet | Platform team | Architecture | Fleet service lifecycle, shared governance, change windows, identity posture |
| Fleet-level management components (VCF Operations, VCF Operations fleet management, VCF Automation) | Platform team | SRE/Operations | Backups, upgrades, integrations, tenant and RBAC guardrails |
| VCF instance | Platform team | Regional ops | Capacity lifecycle, adding domains, instance-level networking standards |
| Management domain | Platform team | VI admin | “Keep the platform running” discipline: patching, certificates, backups |
| VI workload domain | VI admin | Platform team | Day-2 LCM inside guardrails, cluster operations, domain health |
| Domain networking (NSX segments, T0/T1 patterns, edge capacity) | Platform team | Network/security | Network design standards, firewall policy model, edge scaling ceilings |
| VM provisioning and templates | App/platform teams | VI admin | Golden image ownership, config drift control, tagging standards |
| Kubernetes platform on vSphere | App/platform teams | Platform team | Namespace policy, cluster lifecycle, RBAC, platform SLOs |
| VCF Automation catalogs, projects, policies | Platform team | App/platform teams | Self-service guardrails, approvals, quotas, blueprint governance |
| FinOps reporting and showback | Platform team | Finance | Tagging accuracy, allocation rules, cost anomaly response |
Design-time vs day-2 operations
C) Multiple private clouds
Treat these as scope control knobs.
- Fleet count and boundaries
- Instance placement (site and region alignment)
- Domain topology (number of workload domains, shared vs dedicated services)
- Identity model and SSO scope
- Network consumption model (and how much change control you want to enforce)
This split is where most teams get surprised.
- Adding workload domains and clusters
- Capacity rebalancing
- Patch and upgrade sequencing
- RBAC lifecycle and access review
- Drift detection and remediation
Day-0, Day-1, Day-2 Map
This is the simplest operating posture:
| Phase | What you do | Where it happens | Why it matters |
|---|---|---|---|
| Day-0 | Decide VCF private cloud -> fleets -> instances -> domains topology | Architecture/design | This locks your governance and blast radius posture |
| Day-0 | Choose identity model and SSO scope | Architecture/security | Identity boundaries are hard to change later without operational pain |
| Day-0 | Define network consumption model and tenant isolation model | Platform + network/security | Network decisions dictate scale ceilings and operational toil |
| Day-1 | Deploy first fleet + first instance management domain | VCF Installer + first instance management domain | The first instance becomes the anchor location for fleet services |
| Day-1 | Stand up fleet-level management components | Fleet services (hosted in first instance management domain) | This is your “platform services layer” for operations and governance |
| Day-1 | Deploy initial VI workload domain(s) | Instance lifecycle workflows | Workload domains become your default lifecycle and isolation unit |
| Day-2 | Add instances (new sites or regions) | Fleet services + new instance management domain | Expands footprint while keeping governance centralized |
| Day-2 | Add workload domains and clusters | Instance workflows + domain operations | Expands capacity and isolates workloads cleanly |
| Day-2 | Operate identity, automation, and lifecycle | Fleet services | Centralizes day-2 governance across attached instances |
Decision Criteria: Fleet vs Instance vs Domain vs Cluster
VMware Cloud Foundation 9.0 Documentation (Tech Docs): https://techdocs.broadcom.com/us/en/vmware-cis/vcf/vcf-9-0-and-later/9-0.html
VMware Cloud Foundation 9.0 Release Notes: https://techdocs.broadcom.com/us/en/vmware-cis/vcf/vcf-9-0-and-later/vmware-cloud-foundation-90-release-notes.html
Design (VMware Cloud Foundation 9.0): https://techdocs.broadcom.com/us/en/vmware-cis/vcf/vcf-9-0-and-later/9-0/design.html
Architectural Options in VMware Cloud Foundation: https://techdocs.broadcom.com/us/en/vmware-cis/vcf/vcf-9-0-and-later/9-0/design/vmware-cloud-foundation-concepts.html
Fleet Management (VCF Operations): https://techdocs.broadcom.com/us/en/vmware-cis/vcf/vcf-9-0-and-later/9-0/overview-of-vmware-cloud-foundation-9/what-is-vmware-cloud-foundation-and-vmware-vsphere-foundation/vcf-operations-overview/fleet-management.html
VCF Single Sign-On Architecture: https://techdocs.broadcom.com/us/en/vmware-cis/vcf/vcf-9-0-and-later/9-0/fleet-management/what-is/sso-architecture.html
Identity Providers and Protocols Supported for VCF Single Sign-On: https://techdocs.broadcom.com/us/en/vmware-cis/vcf/vcf-9-0-and-later/9-0/fleet-management/what-is/protocols-suported-for–sso.html
Linking vCenter instances in VCF Operations: https://techdocs.broadcom.com/us/en/vmware-cis/vcf/vcf-9-0-and-later/9-0/fleet-management/linking-vcenter-systems-in-vmware-cloud-foundation-operations.html
Quick decision table
| If you need… | Add a fleet | Add an instance | Add a domain | Add a cluster |
|---|---|---|---|---|
| Separate governance plane and change windows | Yes | No | No | No |
| Regulated isolation with hard separation | Often yes | Sometimes | Sometimes | No |
| New site or region footprint | Sometimes | Yes | No | No |
| More lifecycle isolation for workloads | No | No | Yes | Sometimes |
| Different SLA or patch cadence for a workload group | No | No | Yes | Sometimes |
| More capacity in same workload boundary | No | No | No | Yes |
| Separate SSO boundary | Yes (cleanest) | Sometimes | No | No |
| Reduced shared service blast radius | Yes | Sometimes | Sometimes | No |
Architecture Tradeoff Matrix
| Option | Governance isolation | Operational overhead | Scale ceiling | Typical use |
|---|---|---|---|---|
| One private cloud, one fleet | Lowest | Lowest | Medium to high, depending on identity model | Standard enterprise starting point |
| One private cloud, multiple fleets | High | Higher | Higher overall, but duplicated services | Regulated zones, different change windows |
| Multiple private clouds | Highest | Highest | Highest | Mergers, hard org separation, distinct GRC boundaries |
Topology Posture
These are the patterns that inflate toil and create “mystery outages”.
Single site
A clean VCF program usually stabilizes when you stop assigning ownership by product name and start assigning it by boundary:
- One VCF private cloud
- One fleet
- One instance
- Management domain + one or more workload domains
When those boundaries map cleanly to “who owns what”, day-2 operations becomes repeatable instead of heroic.
- One change window for platform services is acceptable for most orgs.
- Use workload domains to isolate “platform workloads” from “business workloads”.
- Treat the management domain as the platform control plane. Keep it boring.
Two sites in one region
Most “VCF design debates” are actually “where do I want the blast radius to stop?”
Most “VCF design debates” are actually “where do I want the blast radius to stop?”
B) One fleet, two instances (one per site)
This post translates that hierarchy into an operating model: who owns what, where day-0/day-1/day-2 work happens, and how topology (single site vs two sites vs multi-region) changes your posture.
- You keep centralized governance while allowing region-specific instances.
- Plan identity carefully. SSO scope can become too large too quickly.
The key is consistency: define targets per boundary and test them.
- You isolate fleet services, identity posture, and change windows.
- You pay in duplicated management footprint and duplicated operational effort.
Use this map to stop “platform work” from leaking into “workload work”, and vice versa.
- Use when organizational or regulatory boundaries require hard separation.
- Expect duplicated tooling and duplicated platform practices unless you standardize aggressively.
Identity Boundaries and SSO Scope
When something breaks, the fastest teams classify the problem by boundary first.
- Admin experience
- Audit posture
- Blast radius during identity incidents
- How your teams move between instances and domains
VCF Single Sign-On models you should reason about
B) One fleet, multiple identity brokers (cross-instance model)
| Model | SSO scope | Availability posture | Operational overhead | When it fits |
|---|---|---|---|---|
| Fleet-wide SSO | Large | Lower (single identity service per fleet) | Low | One fleet, tight governance, smaller instance count |
| Cross-instance SSO | Balanced | Balanced | Medium | Larger fleets, want to limit identity blast radius |
| Single-instance SSO | Small (per instance) | Higher per instance | Higher | Regulated isolation or region autonomy |
If you want clean accountability in VCF 9.0, anchor your operating model to the official hierarchy:
- A common planning guideline is to size a VCF Identity Broker deployment for a limited number of instances. If you intend to exceed that, plan multiple identity brokers or multiple fleets.
Separate IdP and separate SSO boundaries (do both)
Regions are real failure domains. Latency and inter-region dependency will punish “single control plane” assumptions.
Use this as a starting point for your internal RACI.
- Cleanest separation.
- Strongest isolation for regulated tenants.
- Duplicates fleet services footprint.
This is the minimum you want documented before you call the platform “ready”.
- Keeps a single governance plane.
- Reduces blast radius of identity events.
- You must be disciplined about which instances authenticate through which broker.
You want higher availability and operational continuity, but you do not want to turn every incident into a “distributed systems lesson”.
- Resetting VCF Single Sign-On is a non-trivial event. Treat identity changes like a change program, not a quick admin task.
Failure Domain Analysis
Solutions:
Practical blast radius map
| Failure | What breaks first | What usually keeps running | Your first triage question |
|---|---|---|---|
| Fleet services outage (VCF Operations, VCF Automation) | Visibility, governance workflows, self-service provisioning, central policy operations | Existing workloads in domains, core hypervisor operations | Is this governance down or is core infrastructure down? |
| Identity broker outage (in-scope instances) | Logins and SSO flows for in-scope components | Existing workloads and dataplane continue | What is the SSO scope for this identity broker? |
| Instance management domain incident | Instance lifecycle workflows, management vCenter/NSX for that instance | Workloads can keep running, but operations become constrained | Can you still reach workload domain vCenter/NSX? |
| Workload domain incident | Domain-specific provisioning and lifecycle | Other domains and instances | Is isolation working the way you intended? |
| Cluster-level capacity failure | Placement, HA behavior, performance | Other clusters/domains | Did you design cluster boundaries around maintenance and failure? |
Operational Runbook Snapshot
A) Separate fleets, separate IdPs
Fleet services runbook (platform team)
- Backups and restore procedures for:
- VCF Operations
- VCF Operations fleet management
- VCF Automation
- VCF Identity Broker (if used)
- Certificate lifecycle and rotation plan
- Upgrade sequencing plan:
- Fleet-level management components first
- Core instance components next (SDDC Manager, NSX, vCenter, ESX, vSAN)
- Health checks:
- Fleet service availability and telemetry ingestion
- Identity broker health and readiness
- Automation integration health
Real-world RTO/RPO examples you can start with
A) One private cloud, one fleet, multiple instances (region aligned)
- Fleet services (ops and automation):
- RPO: 4 to 24 hours depending on your backup cadence and whether you treat it as “governance state” vs “mission critical”
- RTO: 2 to 8 hours depending on appliance recovery automation and runbook maturity
- Identity services:
- RPO: 1 to 8 hours
- RTO: 1 to 4 hours, because identity outages create broad administrative impact
- Instance management domain:
- RPO: 15 minutes to 4 hours depending on backup tools and datastore replication
- RTO: 4 to 24 hours depending on whether you can rebuild vs restore
Design-time decisions (day-0) are expensive to unwind:
Anti-patterns
B) One private cloud, multiple fleets (region aligned or regulation aligned)
- Treating “fleet” and “instance” as synonyms.
- Putting regulated tenants in the same fleet without a clear identity and change-window strategy.
- Running business workloads in the management domain.
- Sprawling workload domains with no lifecycle boundary strategy.
- Trying to retrofit complex identity changes without a reset and rollback plan.
- Assuming multi-region behaves like a LAN.
Troubleshooting workflow
Solutions:
- Identify the boundary:
- Fleet service issue?
- Identity issue?
- Instance management domain issue?
- Workload domain issue?
- Cluster or host issue?
- Confirm scope:
- One domain, one instance, or the whole fleet?
- Validate impact:
- Provisioning impacted?
- Visibility impacted?
- Existing workloads impacted?
- Choose the right console:
- Fleet-level visibility and operations -> start with VCF Operations
- Instance lifecycle workflows -> validate instance health and management domain state
- Domain operational state -> validate domain vCenter and NSX health
- Stabilize, then remediate:
- Restore service first
- Then fix drift, misconfiguration, or lifecycle backlog
Conclusion
Operational posture:
- VCF private cloud is your organizational boundary for platform outcomes.
- Fleet is where you place shared governance services and shared operational responsibility.
- Instance is your discrete infrastructure footprint, often aligned to a site or region.
- Domain is the lifecycle and isolation boundary you use to protect workloads from each other.
- Cluster is your capacity and maintenance blast radius unit.
Scale note you should plan for:
Sources
Challenge:



