Whisper AI is an advanced automatic speech recognition (ASR) model developed by OpenAI that can transcribe audio into text with impressive accuracy and supports multiple languages. While Whisper AI is primarily designed for batch processing, it can be configured for real-time speech-to-text transcription on Linux.
In this guide, we will go through the step-by-step process of installing, configuring, and running Whisper AI for live transcription on a Linux system.
What is Whisper AI?
Whisper AI is an open-source speech recognition model trained on a vast dataset of audio recordings and it is based on a deep-learning architecture that enables it to:
- Transcribe speech in multiple languages.
- Handle accents and background noise efficiently.
- Perform translation of spoken language into English.
Since it is designed for high-accuracy transcription, it is widely used in:
- Live transcription services (e.g., for accessibility).
- Voice assistants and automation.
- Transcribing recorded audio files.
By default, Whisper AI is not optimized for real-time processing. However, with some additional tools, it can process live audio streams for immediate transcription.
Whisper AI System Requirements
Before running Whisper AI on Linux, ensure your system meets the following requirements:
Hardware Requirements:
- CPU: A multi-core processor (Intel/AMD).
- RAM: At least 8GB (16GB or more is recommended).
- GPU: NVIDIA GPU with CUDA (optional but speeds up processing significantly).
- Storage: Minimum 10GB of free disk space for models and dependencies.
Software Requirements:
- A Linux distribution such as Ubuntu, Debian, Arch, Fedora, etc.
- Python version 3.8 or later.
- Pip package manager for installing Python packages.
- FFmpeg for handling audio files and streams.
Step 1: Installing Required Dependencies
Before installing Whisper AI, update your package list and upgrade existing packages.
sudo apt update [On Ubuntu] sudo dnf update -y [On Fedora] sudo pacman -Syu [On Arch]
Next, you need to install Python 3.8 or higher and Pip package manager as shown.
sudo apt install python3 python3-pip python3-venv -y [On Ubuntu] sudo dnf install python3 python3-pip python3-virtualenv -y [On Fedora] sudo pacman -S python python-pip python-virtualenv [On Arch]
Lastly, you need to install FFmpeg, which is a multimedia framework used to process audio and video files.
sudo apt install ffmpeg [On Ubuntu] sudo dnf install ffmpeg [On Fedora] sudo pacman -S ffmpeg [On Arch]
Step 2: Install Whisper AI in Linux
Once the required dependencies are installed, you can proceed to install Whisper AI in a virtual environment that allows you to install Python packages without affecting system packages.
python3 -m venv whisper_env source whisper_env/bin/activate pip install openai-whisper
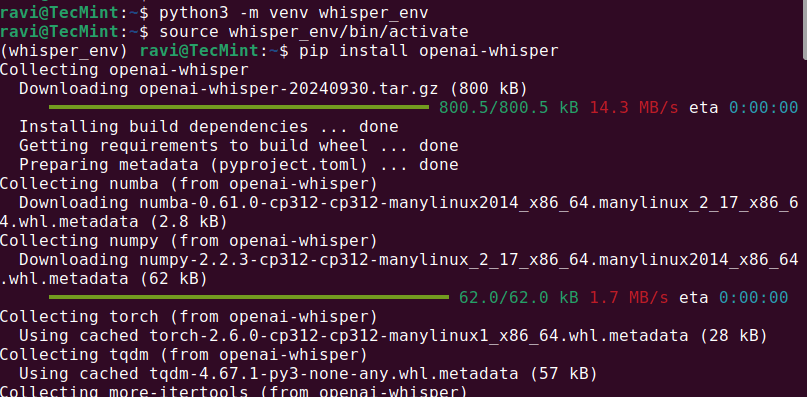
Once the installation is complete, check if Whisper AI was installed correctly by running.
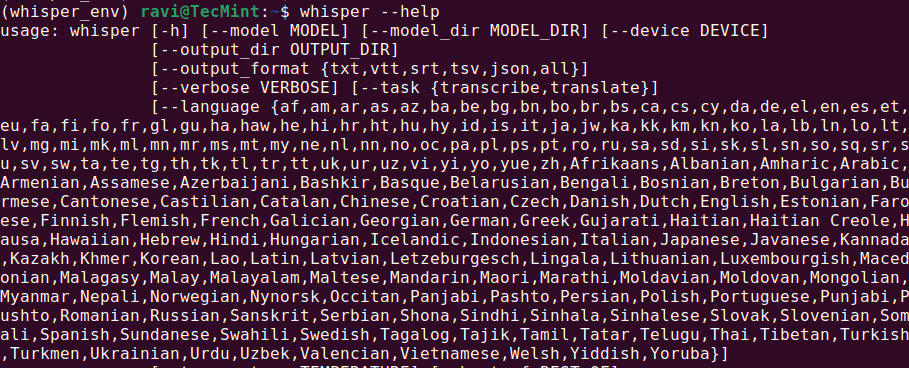
whisper --help
This should display a help menu with available commands and options, which means Whisper AI is installed and ready to use.
Step 3: Running Whisper AI in Linux
Once Whisper AI is installed, you can start transcribing audio files using different commands.
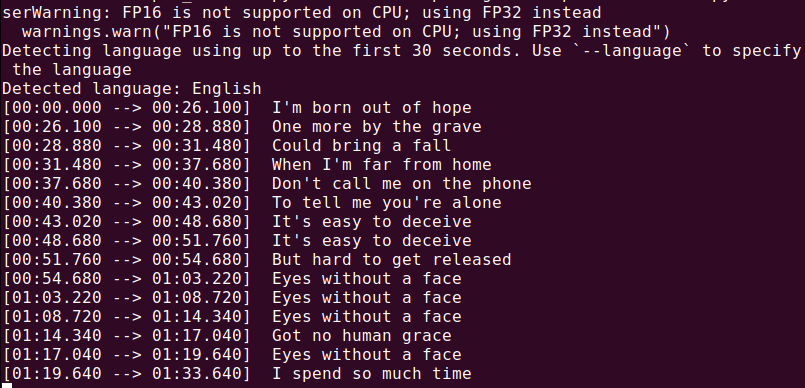
Transcribing an Audio File
To transcribe an audio file (audio.mp3), run:
whisper audio.mp3
Whisper will process the file and generate a transcript in text format.
Now that everything is installed, let’s create a Python script to capture audio from your microphone and transcribe it in real time.
nano real_time_transcription.py
Copy and paste the following code into the file.
import sounddevice as sd
import numpy as np
import whisper
import queue
import threading
# Load the Whisper model
model = whisper.load_model("base")
# Audio parameters
SAMPLE_RATE = 16000
BUFFER_SIZE = 1024
audio_queue = queue.Queue()
def audio_callback(indata, frames, time, status):
"""Callback function to capture audio data."""
if status:
print(status)
audio_queue.put(indata.copy())
def transcribe_audio():
"""Thread to transcribe audio in real time."""
while True:
audio_data = audio_queue.get()
audio_data = np.concatenate(list(audio_queue.queue)) # Combine buffered audio
audio_queue.queue.clear()
# Transcribe the audio
result = model.transcribe(audio_data.flatten(), language="en")
print(f"Transcription: {result['text']}")
# Start the transcription thread
transcription_thread = threading.Thread(target=transcribe_audio, daemon=True)
transcription_thread.start()
# Start capturing audio from the microphone
with sd.InputStream(callback=audio_callback, channels=1, samplerate=SAMPLE_RATE, blocksize=BUFFER_SIZE):
print("Listening... Press Ctrl+C to stop.")
try:
while True:
pass
except KeyboardInterrupt:
print("nStopping...")
Execute the script using Python, which will start listening to your microphone input and display the transcribed text in real time. Speak clearly into your microphone, and you should see the results printed on the terminal.
python3 real_time_transcription.py
Conclusion
Whisper AI is a powerful speech-to-text tool that can be adapted for real-time transcription on Linux. For best results, use a GPU and optimize your system for real-time processing.