TL;DR
- If any Azure IaaS VM in your estate still uses unmanaged disks, it is on a hard clock: after March 31, 2026 those VMs can’t be started, and running or allocated ones are stopped and deallocated.
- Your fastest reality check is the Azure Portal VM list: add the Uses managed disks column/filter and set it to No.
- Treat this like a production change program, not a “click-and-go” task:
- inventory across subscriptions
- identify maintenance windows
- validate dependencies (IPs, availability sets, monitoring, backups)
- schedule conversions in batches
Architecture Diagram
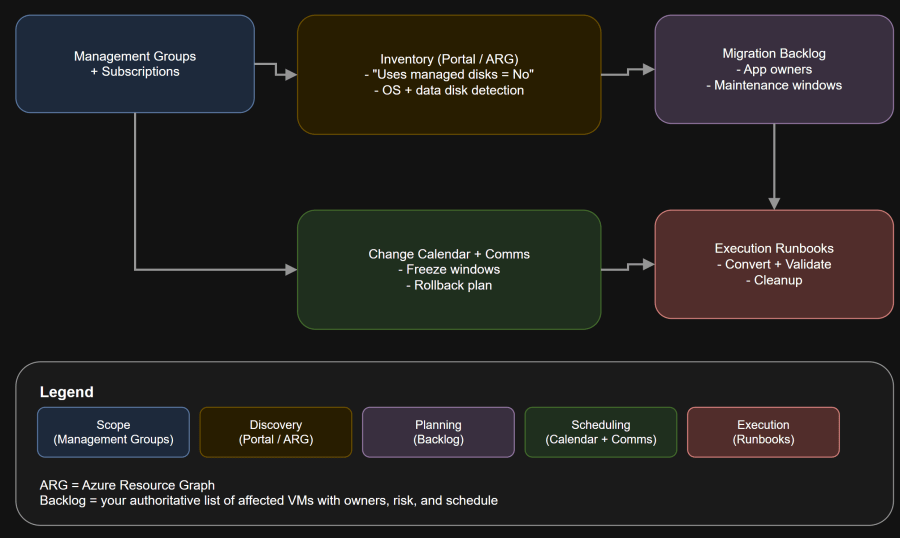
Table of Contents
- Scenario
- What Is Actually Retiring
- Key Challenges
- Quick Risk Assessment
- Assumptions
- Decision Criteria
- Architecture Tradeoff Matrix
- Failure Domain Analysis
- Change Management Considerations
- Summary and Takeaways
- Conclusion
Scenario
What matters operationally:
Use this when you need an answer in minutes.
- critical VMs won’t start
- disaster recovery rehearsals fail unexpectedly
- recovery points restore into unusable configurations
Day-two operations:
What Is Actually Retiring
Use this when you need coverage and repeatability.
Your goal is simple: identify exposure fast, convert safely, and prevent recurrence.
- Your VM storage model changes. You stop managing storage accounts for VM disks.
- Start behavior changes after the deadline. VMs using unmanaged disks become unstartable after end of March 2026.
Key Challenges
- Discovery at scale: It’s easy in one subscription, painful across dozens.
- Availability sets: You can’t mix unmanaged and managed disks in the same availability set. Migration becomes a coordinated batch event.
- Addressing dependencies: Migration can change VM IPs if you were relying on dynamic allocation.
- Day-two readiness: Backups, monitoring, and IaC must be updated to reflect managed disks.
- Operational risk: A “minutes of downtime” change can still trigger extended read-latency effects due to background copy.
Quick Risk Assessment
Fastest check in the Azure Portal
Unmanaged disks are not a theoretical risk. If you still have them, you have a real operational deadline. Inventory now, build a conversion backlog, and execute in controlled waves so you are not negotiating maintenance windows at the last minute.
- Go to Azure Portal → Virtual machines
- Add the column: Uses managed disks
- Filter: Uses managed disks = No
- Export the list and start your backlog
Run this query in Resource Graph Explorer:
- subscription, resource group, VM name, region
- availability set membership (if any)
- application owner
- RTO/RPO and business criticality
- IP dependency notes (static vs dynamic)
- maintenance window constraints
Cross-subscription inventory with Azure Resource Graph
You have Azure IaaS VMs that were built years ago. Some of them were created when unmanaged disks were still common, and the underlying VHDs live in storage accounts as page blobs.
Unmanaged disks are VHDs stored as page blobs in storage accounts and attached to VMs.
Resources
| where type =~ ‘microsoft.compute/virtualmachines’
| extend osDisk = properties.storageProfile.osDisk
| extend usesManagedOsDisk = isnotnull(osDisk.managedDisk)
| where usesManagedOsDisk == false
| project subscriptionId, resourceGroup, name, location,
osDiskVhdUri = tostring(osDisk.vhd.uri)
Migrate your Azure unmanaged disks by March 31, 2026: https://learn.microsoft.com/en-us/azure/virtual-machines/unmanaged-disks-deprecation
Frequently asked questions about disks: https://learn.microsoft.com/en-us/azure/virtual-machines/faq-for-disks
Migrate Azure VMs to Managed Disks in Azure: https://learn.microsoft.com/en-us/azure/virtual-machines/windows/migrate-to-managed-disks
How to identify Azure unmanaged disks and locate the “Migrate to managed disks” option (Q&A): https://learn.microsoft.com/en-us/answers/questions/5709098/how-to-identify-azure-unmanaged-disks-and-locate-t
Resources
| where type =~ ‘microsoft.compute/virtualmachines’
| mv-expand dataDisk = properties.storageProfile.dataDisks
| extend usesManagedDataDisk = isnotnull(dataDisk.managedDisk)
| where usesManagedDataDisk == false
| project subscriptionId, resourceGroup, name, location,
dataDiskVhdUri = tostring(dataDisk.vhd.uri)
PowerShell spot-check
Everything looks “fine” until it isn’t. You discover this retirement late, you miss the window, and suddenly:
- Do you need to preserve the existing VM identity (NICs, disks, extensions)?
- Are you dependent on the current private IP or public IP?
- Is the VM in an availability set, and can you migrate the full set in a window?
Design-time decisions:
- Can your ops team support a background-copy window where read latency may be elevated?
- Do you have monitoring that can detect boot or disk anomalies immediately after restart?
- Do you have rollback options that your change board will accept?
Architecture Tradeoff Matrix
| Approach | When it’s best | Downtime profile | Blast radius | Operational notes |
|---|---|---|---|---|
| Convert existing VM disks to managed | Most common. Minimal architecture change | Short VM downtime for stop/convert/start, plus possible post-cutover read-latency window | Per VM or per availability set | Must plan for IP behavior and availability set constraints |
| Rebuild VM from managed disks (new VM) | When you want to modernize NIC/IP, images, or naming | Higher because you cut over to a new VM instance | App-level | Cleaner rollback and modernization, but more moving parts |
| Modernize to a higher-level platform | When VM is legacy debt and you have time | Project-sized | App/system-level | Not a “six weeks to deadline” move for most orgs |
Failure Domain Analysis
Where this goes wrong in real life:
- Availability sets: You discover late that a “single VM change” is really “all VMs in the set change.”
- Dynamic IP dependencies: Some workloads still hardcode private IPs in config files, firewall rules, or downstream systems.
- Hidden consumers of the storage account: Diagnostics, scripts, or legacy tooling might assume disks live in a storage account container.
Change Management Considerations
- Treat this as a deadline-driven reliability change, not an optimization.
- Convert in batches:
- low-risk dev/test first
- then single-instance production
- then availability sets
- Require a pre-flight checklist:
- backups verified
- VM extensions healthy
- static IP set if needed
- monitoring alert routes validated
- Document rollback: what “good” looks like, what triggers rollback, and how you recover.
Summary and Takeaways
- Your first win is visibility: find unmanaged disks across every subscription.
- Your second win is scheduling: the conversion is fast, but the coordination is not.
- Your third win is prevention: once you’re clean, enforce managed disks via policy and CI guardrails.
Conclusion
# Lists VMs in the current subscription that use unmanaged OS disks
Get-AzVM | Where-Object { $_.StorageProfile.OsDisk.ManagedDisk -eq $null } |
Select-Object ResourceGroupName, Name, Location
Decision Criteria
What you capture in the backlog: