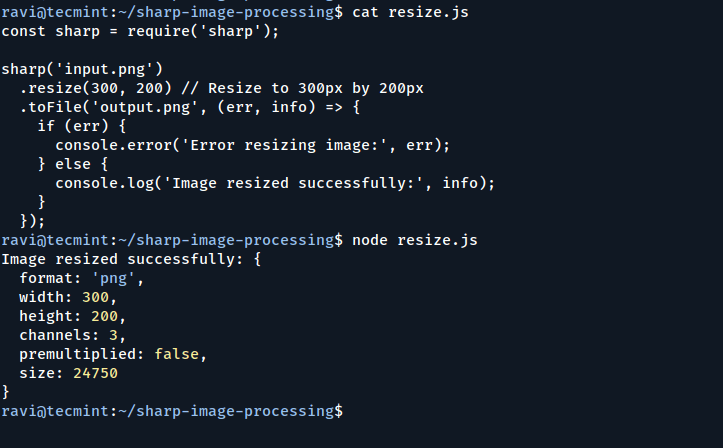
TL;DR
This is the “where do we do the thing” map you want in every runbook.
- Organizational private cloud (program term) -> VCF Fleet -> VCF Instance -> VCF Domains (management and workload) -> vSphere clusters
- A fleet is the boundary for shared fleet services (operations, automation, identity, governance). It is not “one shared SDDC management plane.”
- An instance is the boundary for a discrete SDDC footprint with its own management domain and workload domains.
- A domain is your lifecycle and isolation unit. It is where you place blast radius and change windows on purpose.
- Scope and code levels referenced in this post (VCF 9.0 GA BOM):
- VCF 9.0 Release: Build 24755599
- VCF Installer: 9.0.1.0 Build 24962180 (required to deploy VCF 9.0.0.0 components)
- SDDC Manager: 9.0.0.0 Build 24703748
- vCenter: 9.0.0.0 Build 24755230
- ESX: 9.0.0.0 Build 24755229
- NSX: 9.0.0.0 Build 24733065
- VCF Operations: 9.0.0.0 Build 24695812
- VCF Operations fleet management: 9.0.0.0 Build 24695816
- VCF Automation: 9.0.0.0 Build 24701403
- VCF Identity Broker: 9.0.0.0 Build 24695128
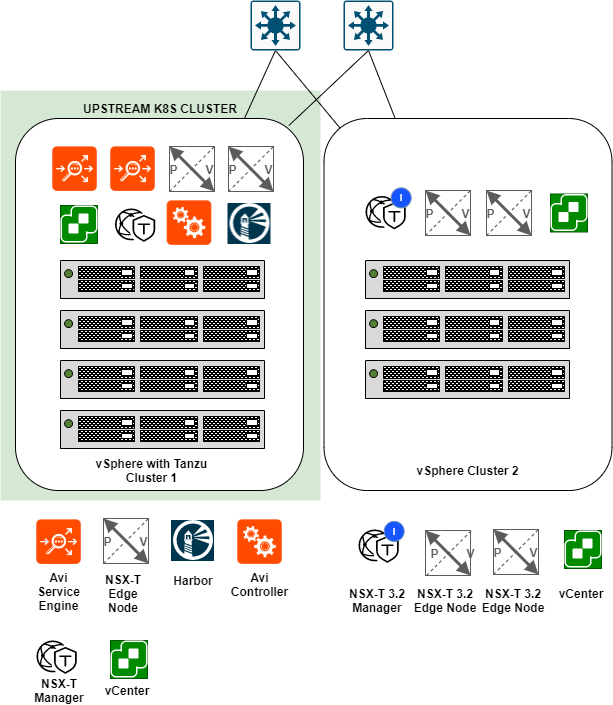
Architecture Diagram
Table of Contents
- Scenario
- Series map
- Assumptions
- Core vocabulary your org should standardize
- The hierarchy that prevents org-wide confusion
- What the fleet actually owns vs what stays per instance
- Day-0, day-1, day-2 map
- Challenge: one private cloud vs multiple fleets
- Deployment posture patterns
- Who owns what
- Failure domain analysis
- Anti-patterns
- Summary and Takeaways
- Conclusion
Scenario
What keeps running:
- “What is VCF actually managing?”
- “What breaks if something fails?”
- “Who is on point when something needs to change?”
- “How do we scale without turning upgrades into drama?”
Your platform team must translate that into platform objects:
- Fleet and instance used as synonyms.
- Change windows scheduled at the wrong layer.
- Mis-scoped identity decisions that are expensive to unwind.
- Incorrect assumptions about blast radius.
Series map
If you do not do this translation explicitly, you will end up with “one private cloud” being interpreted as “one vCenter,” which is the wrong mental model in VCF 9.0.
- Part 1 (this post): Vocabulary, hierarchy, and ownership boundaries that stop misunderstandings.
- Part 2: The new management layer in VCF 9.0: VCF Installer, VCF Operations fleet management, and where lifecycle actually runs.
- Part 3: Topology patterns and isolation: single site, two sites in one region, multi-region, and the identity options that go with them.
- Later: Brownfield converge/import from a large vSphere estate.
Assumptions
- You are greenfield for VCF 9.0 GA.
- You plan to deploy both VCF Operations and VCF Automation from day-1, not phased.
- You want patterns for single site, two sites in one region, and multi-region.
- You may need either:
- Shared SSO boundary (single enterprise),
- Separate SSO boundaries (regulated isolation or hard multi-tenancy).
Core vocabulary your org should standardize
VCF 9.0 becomes easier to operate when you stop thinking “one vCenter” and start thinking in fleet, instance, and domain boundaries.
| Term | What it means in your operating model | What it is not |
|---|---|---|
| Organizational private cloud | Your program label for “the service you provide” (budget, roadmap, stakeholders) | Not a VCF object you create in the UI |
| VCF fleet | Governance and shared-services boundary for fleet management components | Not “one shared vCenter” |
| Fleet management components | Shared services for operations, lifecycle, automation, identity | Not the same thing as SDDC Manager |
| VCF instance | A discrete VCF deployment footprint (management domain + workload domains) | Not a tenant boundary by default |
| VCF domain | Lifecycle and isolation boundary (management domain or workload domain) | Not always a “site” |
| Management domain | A domain that hosts the instance’s core management components (and fleet components for the first instance) | Not “never runs workloads” (you should still avoid putting random workloads here) |
| Workload domain | A domain built to run consumer workloads | Not a catch-all dumping ground for everything |
| vSphere cluster | The scale unit inside a domain | Not the lifecycle boundary for VCF components |
Recommended internal phrasing
Best when:
- Fleet = shared fleet services and governance scope
- Instance = discrete VI footprint with its own core management stack
- Domain = lifecycle and workload isolation boundary
- Cluster = capacity and scaling unit
The hierarchy that prevents org-wide confusion
You are building a private cloud, but you manage fleets, instances, and domains
What breaks:
Operational posture:
- Fleets
- Instances
- Domains
Day-2 outcome you want:
The hierarchy you should teach
- Fleet is the umbrella for shared services and governance.
- Instances are discrete deployments under that umbrella.
- Domains are where lifecycle and isolation live.
- Clusters are where you scale capacity.
What usually keeps running:
What the fleet actually owns vs what stays per instance
Common patterns:
Fleet scope
Use this to set expectations with leadership.
- VCF Operations as the day-to-day operate interface.
- VCF Operations fleet management for lifecycle of management components (download binaries, deploy, patch, upgrade, backup workflows).
- VCF Automation for self-service consumption and governance.
- VCF Identity Broker to enable VCF Single Sign-On models (optional designs, but still a fleet concern).
A practical default:
- A fleet issue impacts visibility, governance, lifecycle workflows, and self-service.
- A fleet issue does not delete your vCenter or turn off your ESX hosts.
Instance scope
A practical default:
- If an instance’s SDDC Manager or management domain is down, you lose instance-level lifecycle and potentially some management operations.
- Workloads may continue running, but your ability to change and recover cleanly is reduced.
Domain scope
A practical default:
- Domain-level incidents are the “tenant impact” layer.
- Domain-level upgrades can be scheduled per domain, not “everything at once.”
Day-0, day-1, day-2 map
These are the patterns that create long-term operational pain.
Day-0 design decisions
Tradeoffs:
- Fleet count and scope (how many governance boundaries you want)
- Instance alignment strategy (site, region, failure domain, or org boundary)
- Domain strategy (how many workload domains, what is isolated)
- Identity model choice (shared vs separate SSO boundaries)
- Network segmentation for management components and workload domains
- Backup and restore architecture for fleet management components
This topic is usually too big for one post, so here is the split:
- You can answer “what is the blast radius if X fails?” without hand-waving.
Day-1 bring-up
These choices are difficult or expensive to reverse later:
- Deploy the first fleet (which includes deploying the first instance with its initial management domain and hosting fleet components in that initial management domain)
- Deploy additional instances (if needed)
- Create initial workload domain(s)
- Deploy and integrate VCF Operations and VCF Automation (your chosen posture is “both from day-1”)
Best when:
- A working operating model where platform team, VI admin, and app/platform teams can each do their jobs without stepping on each other.
Day-2 operations
This is the most important correction to get right.
- Lifecycle operations (patch, upgrade, drift management)
- Capacity management and domain scaling
- Identity lifecycle (cert rotation, provider changes, recovery)
- Adding instances to a fleet
- Adding workload domains and mapping them into your cloud org structure
- Incident response based on correct blast radius
If you want alignment fast, standardize on this hierarchy and ownership split:
- Changes are scoped to the right layer, and rollback paths are clear.
Challenge: one private cloud vs multiple fleets
The challenge
In VCF 9.0, a workload domain commonly has:
- Scale
- Isolation
- Independent change windows
- Regulatory separation (sometimes)
The fleet gives you shared services across multiple instances, typically including:
Solutions
Solution A: One private cloud program, one fleet
Your main design fork is: “Do I want a single operational footprint or two?”
- You have one enterprise governance boundary.
- You want the simplest operating model.
- You can tolerate a single fleet services layer as a shared dependency.
Your main design fork is: “Do I want a single operational footprint or two?”
- You have regulated tenants or business units requiring separation.
- You want different change windows per fleet.
- You want to reduce fleet-level blast radius.
Your main design fork is: “Do I want a single operational footprint or two?”
- You have hard organizational separation (budget, risk, compliance, separate leadership).
- You expect different service tiers and roadmaps.
Day-1 is about standing up the first production-quality slice:
- Highest overhead.
- Harder to create consistent enterprise-wide consumption patterns.
Architecture tradeoff matrix
| Decision | Isolation | Scale | Ops overhead | Upgrade coordination | Typical use case |
|---|---|---|---|---|---|
| One fleet | Medium | High | Lowest | Highest coupling at fleet layer | Single enterprise platform |
| Multiple fleets | High | High | Medium to high | Independent per fleet | Regulated isolation, large enterprises |
| Multiple programs | Very high | Varies | Highest | Fully independent | Separate business entities |
Deployment posture patterns
Single site
You are balancing:
- One fleet
- One instance
- One management domain
- Multiple workload domains aligned to isolation needs (prod vs non-prod, regulated vs general, platform vs apps)
This is the “stop paging the wrong team” table.
- Simple identity.
- Simple change calendar.
- Domain boundaries do most of the work for isolation.
Two sites in one region
This is the “stop paging the wrong team” table.
- Instance boundaries are often your “site boundary.”
- Domains remain your “tenant and lifecycle boundary.”
Multi-region
This is the “stop paging the wrong team” table.
- Multi-fleet becomes attractive when you want regional autonomy and reduced shared dependency.
Who owns what
In VCF terms, that means deciding how many fleets you run.
| Scope | Platform team (cloud foundation) | VI admin (infrastructure) | App/platform teams (consumers) |
|---|---|---|---|
| Fleet services (VCF Operations, fleet management, Automation, Identity Broker) | Own and operate. Standards, backups, certs, lifecycle, RBAC | Support integration points for their instances | Consume. No admin of fleet services |
| Fleet topology (how many fleets, where) | Accountable decision | Consulted | Informed |
| Instance management stack (SDDC Manager, mgmt vCenter, mgmt NSX) | Guardrails and standards | Own and operate day-2 | Not responsible |
| Domain lifecycle (create, patch, expand, decommission) | Guardrails and patterns | Execute and operate | Consume outcomes |
| Workload operations inside guest OS and Kubernetes | Not responsible | Not responsible | Own and operate |
Design-time vs day-2 ownership
- Design-time: Platform team owns topology and identity model decisions.
- Day-2: VI admins own SDDC-level lifecycle execution. Platform team owns fleet services lifecycle. App/platform teams own workload lifecycle inside the platform.
Failure domain analysis
Each instance remains a discrete SDDC management footprint:
Fleet services failure
Best when:
- Centralized visibility and governance
- Automation workflows and self-service
- Fleet-level lifecycle workflows
Best when:
- Instance-level lifecycle orchestration
- Some management operations for domains in that instance
- Potentially NSX control plane for that instance if scoped there
Best when:
- Workloads and services in that domain
- Tenant-specific operations
Domains are where you place:
- Other domains in the instance
- Other instances in the fleet
Anti-patterns
Day-2 is where most pain lives if the model is wrong:
- Treating fleet and instance as synonyms.
- Planning change windows at “the vCenter level” instead of domain and fleet services levels.
- Putting regulated tenants into the same fleet without a governance and identity strategy.
- Running meaningful production workloads in the management domain because “there is spare capacity.”
- Out-of-band changes without an inventory and drift practice.
Summary and Takeaways
You want “one private cloud” from a service catalog perspective, but you also need:
- Fleet is a shared services and governance boundary, not a shared vCenter boundary.
- Instance is your discrete SDDC footprint boundary.
- Domain is your lifecycle, isolation, and blast radius boundary.
- “Private cloud” is what you call the program. Fleets, instances, and domains are what you operate.
- If you standardize vocabulary now, you will reduce friction in design reviews, incident triage, and change governance.
Conclusion
Operational implication:
Operational implication:
- Clear ownership and escalation paths
- Predictable blast radius
- Change windows that match the topology
- A platform posture that scales from single site to multi-region without rewriting your operating model

![12 Must-Have Linux Console [Terminal] File Managers](https://megazencarthosting.com/wp-content/uploads/2024/09/12-must-have-linux-console-terminal-file-managers.png)