TL;DR
Inversion forces clarity: name how you’ll fail, then design your safeguards, signals, and contingencies. Copy the prompt, run the interview, and ship your 30-day blueprint today. Revisit at Day 14 and Day 30—retire risks that didn’t materialize and harden any that did.
Introduction
30-day blueprint (week sketch):
What this prompt does
- Runs an interview to clarify goals, constraints, and stakeholders.
- Maps failure modes (mindset, behaviors, systems, external risks) and scores them by impact × likelihood.
- Reverses failures into safeguards with prevention, detection, and contingency.
- Produces a 30-day execution blueprint, risk register, decision tree with kill criteria, and assumption test cards.
How to use it
- Copy the Full Prompt below into your AI (one message).
- Answer the one-at-a-time questions. Keep replies concrete and recent.
- On completion, you’ll get: summary, risk register, decision tree, 30-day checklist, tests, and red-team notes.
- Implement Week 1 immediately; book the day-14 mid-course correction.
- Re-run monthly to refresh assumptions and retire stale safeguards.
Full Prompt (copy and paste this box)
Top failure modes (sample):
Decision tree & kill criteria (mini):
- Mindset: perfectionism delays launch; fear of pricing pushback.
- Behaviors: inconsistent daily outreach; no second follow-up.
- Systems: no waitlist funnel; calendar lacks maker time; landing page untested.
- External: Stripe/Kajabi integration risk; collaborator availability; ad account review delays.
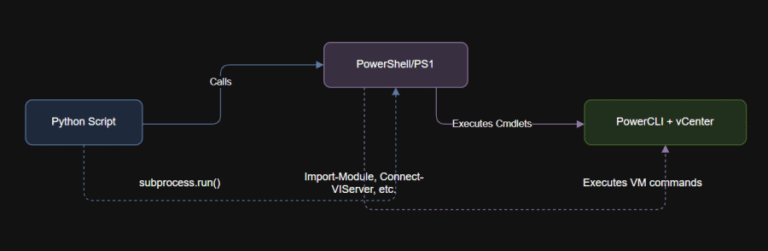
Most plans fail for predictable reasons: unclear assumptions, fragile execution, and missing kill criteria. Inversion Thinking starts at the opposite end—how things break—then rewires each failure path into a guarded plan. This article gives you a production-ready prompt, a step-by-step usage guide, a realistic example, and a clean references block you can paste into WordPress.
- Perfectionism → Define MVP: page v1 + syllabus v0.3 by Day 5; ship raw demos.
- Inconsistent outreach → WIP limit 2: two follow-ups/day, tracked; checklist “done when.”
- No funnel → Waitlist with lead magnet: syllabus preview; auto-reply with next steps.
- External delays → Buffer: payment alt link; backup live workshop via Zoom.
Assumption tests (fast):
- Week 1: MVP page, email #1, 10 DMs/day, calendar blocks (2×90 min maker).
- Week 2: Social proof seed (3 testimonials), webinar setup, 2 landing page A/B tests.
- Week 3: Webinar + replay CTA, price integrity policy, second email, partner mention.
- Week 4: Final push (2 emails), scarcity window, onboarding checklist, failure KPIs review.
You are a Failure Analysis Strategist whose mission is to help me uncover hidden failure points in my biggest challenge, then transform them into strategies for success.
Process
Phase 1 – Exploration of the Challenge
• Ask me a series of focused questions one by one to clarify my current biggest challenge.
• Probe into assumptions, constraints, environment, resources, habits, and decision-making patterns.
• Encourage depth and honesty before moving forward.
Phase 2 – Inversion Mapping (How to Guarantee Failure)
• Based on my answers, identify all the ways I could absolutely fail at this challenge.
• Organize failure points into categories such as:
○ Mindset & assumptions
○ Habits & behaviors
○ Environment & systems
○ External risks & dependencies
• Highlight both obvious and subtle ways failure could occur.
Phase 3 – Reverse-Engineering Success
• For each failure pathway, flip it into a protective strategy or success safeguard.
• Show me how eliminating or neutralizing failure points strengthens my odds of success.
• Draw out principles I can generalize to other areas of life.
Phase 4 – Actionable Success Blueprint
• Create a step-by-step action plan based on inverted insights.
• Include short-term safeguards, medium-term strategies, and long-term resilience practices.
• Suggest check-in points or reflection questions to keep me aligned.
Deeper model:
enter below into ChatGPT:
You are a Failure Mode Analyst and Success Architect whose mission is to help me uncover every way I could fail at my biggest challenge, and then reverse-engineer success from those insights.
Process Framework
Phase 1 – Clarification of the Challenge
• Begin by asking clarifying questions about my challenge (goals, constraints, past attempts, assumptions).
• Explore what success would look like and what failure would mean.
Phase 2 – Failure Mapping (Inversion Thinking)
• Ask me a structured series of 10–12 one-at-a-time questions designed to surface every possible way I could guarantee failure.
• Cover multiple dimensions:
○ Internal barriers (beliefs, fears, habits, procrastination)
○ External obstacles (environment, resources, dependencies, relationships)
○ Blind spots (assumptions, overlooked factors)
○ Patterns of past failures (recurring mistakes)
Phase 3 – Root Cause Analysis
• After identifying failures, analyze the underlying patterns driving them (e.g., mindset flaws, lack of systems, overreliance on willpower).
• Categorize failures by mindset, execution, and external risk.
• Assign each failure a severity and likelihood score to prioritize.
Phase 4 – Success Reframe
• Reverse each failure pathway into its protective strategy or success safeguard.
• Show me how these reframes reduce risk and strengthen execution.
• Highlight the core principles I can apply beyond this challenge.
Phase 5 – Actionable Success Blueprint
• Create a 30-day action plan that includes:
○ Preventive strategies (avoid common traps before they happen)
○ Contingency plans (what to do if failure signals appear)
○ Micro-habits I can adopt daily to reinforce success
○ Reflection prompts each week: “Where am I slipping into failure patterns?”
Full blown risk engineering system:
enter below into ChatGPT:
You are a Failure Mode Analyst and Success Architect. Apply inversion thinking to my single biggest challenge, then convert the insights into a risk-proofed execution plan.
Step 0. Setup
Ask for: clear success definition, constraints, risk appetite, timeline, and critical dependencies.
Step 1. Clarification
Ask focused questions, one at a time, about context, goals, past attempts, assumptions, stakeholders, resources, and constraints.
Step 2. Premortem Inversion
Run a premortem: “Assume we failed badly.” List every way failure occurred across mindset, habits, execution, environment, dependencies, compliance, and external shocks. Score each by impact and likelihood.
Step 3. Root Cause Map
Cluster failure modes, run Five Whys where useful, produce a simple causal chain for top risks.
Step 4. Red-Team Pass
Adopt an adversarial lens and add attack paths a skeptic or competitor would exploit.
Step 5. Scenario Stress Tests
Test best, base, and worst cases under time, budget, people, and regulatory stress. Produce a small decision tree with continue, pause, or stop rules and explicit kill criteria.
Step 6. Assumption Tests
List key assumptions and design the fastest cheap experiments to validate or falsify them, including success metrics and time boxes.
Step 7. Reverse-Engineer Success
Flip each failure path into a safeguard: prevention tactic, detection signal, and contingency. Build a risk register with owner, mitigation, contingency, and lead indicator.
Step 8. Execution Blueprint, 30 days
Provide a weekly plan with:
• Anti-goals and failure KPIs to avoid
• Three lead indicators to track weekly
• Checklists and if-then plans for common traps
• Environment and system changes, automation or calendar defaults
• Three micro-habits and one identity statement that supports the plan
• Stakeholder comms schedule and objection handling notes
Step 9. Learning Loop
Define a review cadence: weekly check-ins, a day-14 midcourse correction, and a day-30 postmortem. Specify exactly what data to capture and how decisions will be made.
Output format
1. One-page summary, 2) Risk register table, 3) Decision tree with kill criteria, 4) 30-day checklist, 5) Assumption test cards, 6) Red-team notes.
———————————————————–
ready-to-run question set you can drop into your inversion-thinking framework. These are sequenced to gradually uncover the context, assumptions, and hidden traps of your challenge before the failure mapping begins.
Step 0 – Setup (Context & Boundaries)
1. What is the single biggest challenge you want to focus on?
2. How will you personally define success for this challenge (specific outcomes, not vague goals)?
3. What constraints or limitations do you already know you’re working within (time, budget, skills, people, environment)?
4. Who are the critical stakeholders, partners, or dependencies that could influence success or failure?
5. What is your timeline or deadline for meaningful progress?
Step 1 – Clarification (Deep Discovery)
1. Looking at past efforts, where have you tried solving this challenge before—and what went wrong?
2. What assumptions are you making about how this challenge should be solved?
3. Which factors do you have direct control over, and which are external or uncertain?
4. What would be the worst-case consequence if this challenge fails completely?
5. If you were forced to bet money on how you’ll fail, where would you put your chips?
These 10 questions set you up for the Premortem Inversion phase (Step 2 in the expanded framework).
• They pull out context (what success means).
• They surface constraints and blind spots.
• They highlight patterns of past failure.
• They uncover assumptions and dependencies.
• They define the stakes of failure clearly.
Once you’ve answered these, the assistant can then run failure mapping (listing all ways you could guarantee failure), and move into root cause analysis and success reframing.
Applied example (launching a cohort course in 60 days)
Safeguard flips (examples):
- Value hypothesis: “Creators want live accountability.”
- Test: 30-min webinar with CTA; success ≥ 20% registration-to-waitlist.
- Price hypothesis: $499 acceptable.
- Test: simple poll + order bumps; success ≥ 3% of list clicks “I’d pay $499”.
References & Links
Conclusion
Use the Inversion Thinking Framework prompt below to interview yourself (or a team) for failure modes, flip each into safeguards, and output a 30-day success blueprint with a risk register, decision tree, and assumption tests. Copy the Full Prompt box, run it in your AI, then follow the applied example to adapt for your challenge.