If you’re just starting your journey into data science, you might think it’s all about Python libraries, Jupyter notebooks, and fancy machine learning algorithms and while those are definitely important, there’s a powerful set of tools that often gets overlooked: the humble command line.
I’ve spent over a decade working with Linux systems, and I can tell you that mastering these command-line tools will make your life significantly easier. They’re fast, efficient, and often the quickest way to peek at your data, clean files, or automate repetitive tasks.
To make this tutorial practical and hands-on, we’ll use a sample e-commerce sales dataset throughout this article. Let me show you how to create it first, then we’ll explore it using all 10 tools.
Create the sample file:
cat > sales_data.csv << 'EOF' order_id,date,customer_name,product,category,quantity,price,region,status 1001,2024-01-15,John Smith,Laptop,Electronics,1,899.99,North,completed 1002,2024-01-16,Sarah Johnson,Mouse,Electronics,2,24.99,South,completed 1003,2024-01-16,Mike Brown,Desk Chair,Furniture,1,199.99,East,completed 1004,2024-01-17,John Smith,Keyboard,Electronics,1,79.99,North,completed 1005,2024-01-18,Emily Davis,Notebook,Stationery,5,12.99,West,completed 1006,2024-01-18,Sarah Johnson,Laptop,Electronics,1,899.99,South,pending 1007,2024-01-19,Chris Wilson,Monitor,Electronics,2,299.99,North,completed 1008,2024-01-20,John Smith,USB Cable,Electronics,3,9.99,North,completed 1009,2024-01-20,Anna Martinez,Desk,Furniture,1,399.99,East,completed 1010,2024-01-21,Mike Brown,Laptop,Electronics,1,899.99,East,cancelled 1011,2024-01-22,Emily Davis,Pen Set,Stationery,10,5.99,West,completed 1012,2024-01-22,Sarah Johnson,Monitor,Electronics,1,299.99,South,completed 1013,2024-01-23,Chris Wilson,Desk Chair,Furniture,2,199.99,North,completed 1014,2024-01-24,Anna Martinez,Laptop,Electronics,1,899.99,East,completed 1015,2024-01-25,John Smith,Mouse Pad,Electronics,1,14.99,North,completed 1016,2024-01-26,Mike Brown,Bookshelf,Furniture,1,149.99,East,completed 1017,2024-01-27,Emily Davis,Highlighter,Stationery,8,3.99,West,completed 1018,2024-01-28,NULL,Laptop,Electronics,1,899.99,South,pending 1019,2024-01-29,Chris Wilson,Webcam,Electronics,1,89.99,North,completed 1020,2024-01-30,Sarah Johnson,Desk Lamp,Furniture,2,49.99,South,completed EOF
Now let’s explore this file using our 10 essential tools!
1. grep – Your Pattern-Matching Tool
Think of grep command as your data detective, as it searches through files and finds lines that match patterns you specify, which is incredibly useful when you’re dealing with large log files or text datasets.
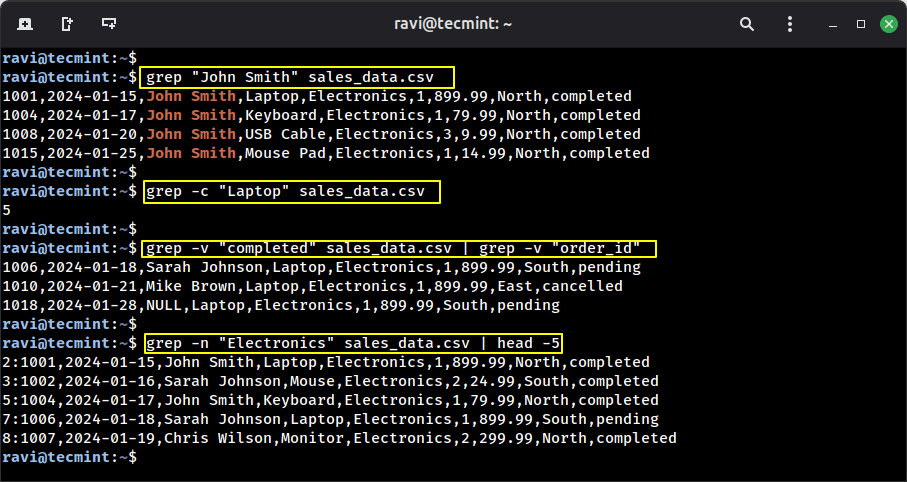
Example 1: Find all orders from John Smith.
grep "John Smith" sales_data.csv
Example 2: Count how many laptop orders we have.
grep -c "Laptop" sales_data.csv
Example 3: Find all orders that are NOT completed.
grep -v "completed" sales_data.csv | grep -v "order_id"
Example 4: Find orders with line numbers.
grep -n "Electronics" sales_data.csv | head -5
2. awk – The Swiss Army Knife for Text Processing
awk is like a mini programming language designed for text processing, which is perfect for extracting specific columns, performing calculations, and transforming data on the fly.
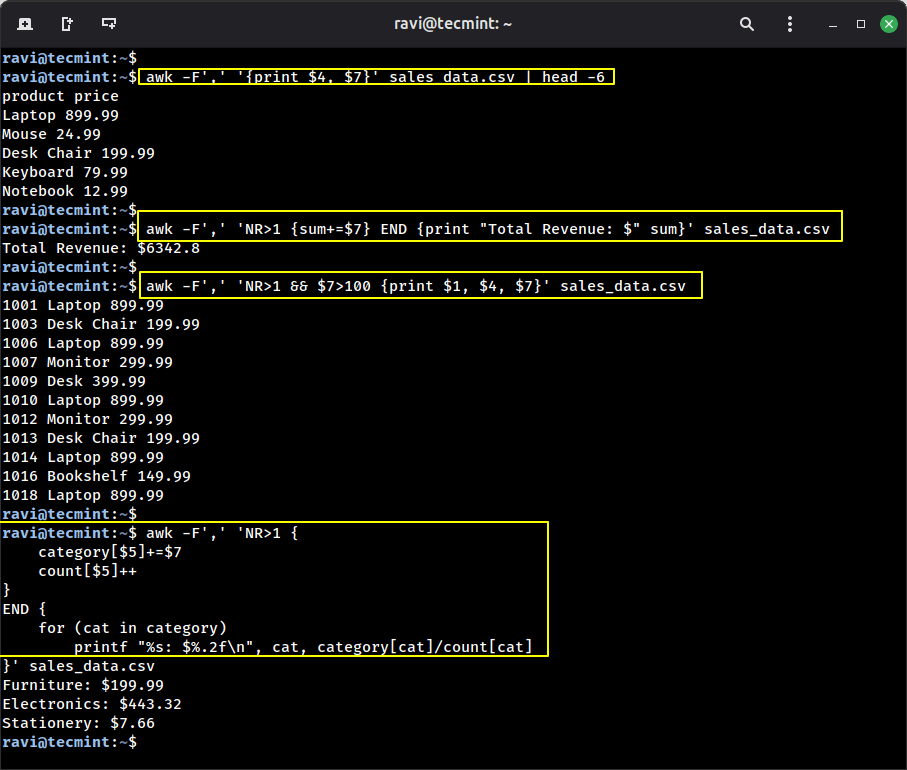
Example 1: Extract just product names and prices.
awk -F',' '{print $4, $7}' sales_data.csv | head -6
Example 2: Calculate total revenue from all orders.
awk -F',' 'NR>1 {sum+=$7} END {print "Total Revenue: $" sum}' sales_data.csv
Example 3: Show orders where the price is greater than $100.
awk -F',' 'NR>1 && $7>100 {print $1, $4, $7}' sales_data.csv
Example 4: Calculate the average price by category.
awk -F',' 'NR>1 {
category[$5]+=$7
count[$5]++
}
END {
for (cat in category)
printf "%s: $%.2fn", cat, category[cat]/count[cat]
}' sales_data.csv
3. sed – The Stream Editor for Quick Edits
sed is your go-to tool for find-and-replace operations and text transformations. It’s like doing “find and replace” in a text editor, but from the command line and much faster.
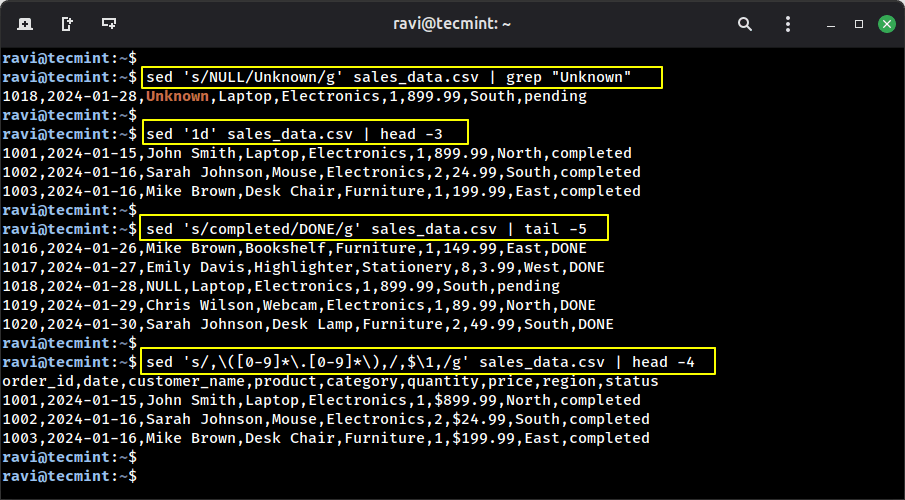
Example 1: Replace NULL values with “Unknown“.
sed 's/NULL/Unknown/g' sales_data.csv | grep "Unknown"
Example 2: Remove the header line.
sed '1d' sales_data.csv | head -3
Example 3: Change “completed” to “DONE“.
sed 's/completed/DONE/g' sales_data.csv | tail -5
Example 4: Add a dollar sign before all prices.
sed 's/,([0-9]*.[0-9]*),/,$,/g' sales_data.csv | head -4
4. cut – Simple Column Extraction
While awk is powerful, sometimes you just need something simple and fast, that’s where cut command comes in, which is specifically designed to extract columns from delimited files.
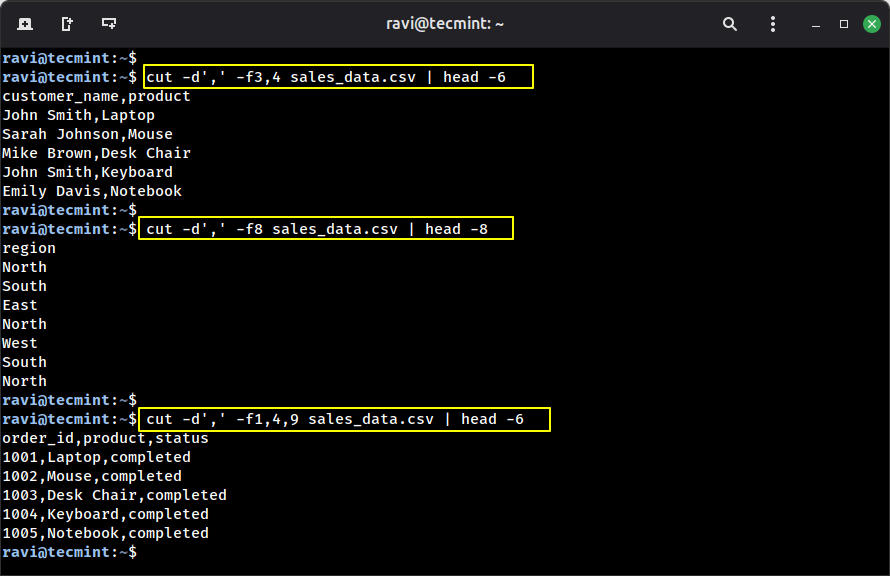
Example 1: Extract customer names and products.
cut -d',' -f3,4 sales_data.csv | head -6
Example 2: Extract only the region column.
cut -d',' -f8 sales_data.csv | head -8
Example 3: Get order ID, product, and status.
cut -d',' -f1,4,9 sales_data.csv | head -6
5. sort – Organize Your Data
Sorting data is fundamental to analysis, and the sort command does this incredibly efficiently, even with files that are too large to fit in memory.
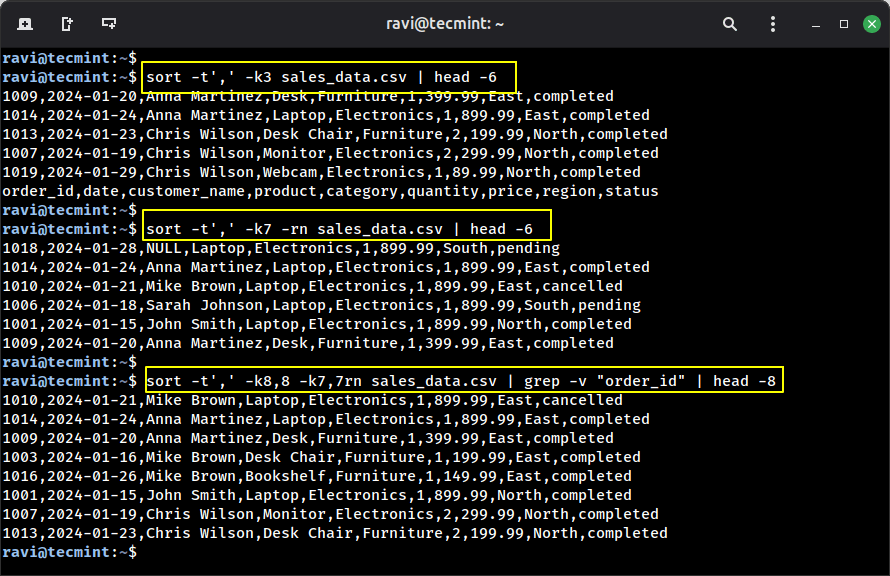
Example 1: Sort by customer name alphabetically.
sort -t',' -k3 sales_data.csv | head -6
Example 2: Sort by price (highest to lowest).
sort -t',' -k7 -rn sales_data.csv | head -6
Example 3: Sort by region, then by price.
sort -t',' -k8,8 -k7,7rn sales_data.csv | grep -v "order_id" | head -8
6. uniq – Find and Count Unique Values
uniq command helps you identify unique values, count occurrences, and find duplicates, which is like a lightweight version of pandas’ value_counts().
uniq only works on sorted data, so you’ll usually pipe it with sort.
Example 1: Count orders by region.
cut -d',' -f8 sales_data.csv | tail -n +2 | sort | uniq -c
Example 2: Count orders by product category.
cut -d',' -f5 sales_data.csv | tail -n +2 | sort | uniq -c | sort -rn
Example 3: Find which customers made multiple purchases.
cut -d',' -f3 sales_data.csv | tail -n +2 | sort | uniq -c | sort -rn
Example 4: Show unique products ordered.
cut -d',' -f4 sales_data.csv | tail -n +2 | sort | uniq
7. wc – Word Count (and More)
Don’t let the name fool you, wc (word count) is useful for much more than counting words, which is your quick statistics tool.
Example 1: Count the total number of orders (minus header).
wc -l sales_data.csv
Example 2: Count how many electronics orders.
grep "Electronics" sales_data.csv | wc -l
Example 3: Count total characters in the file.
wc -c sales_data.csv
Example 4: Multiple statistics at once.
wc sales_data.csv
8. head and tail – Preview Your Data
Instead of opening a massive file, use head command to see the first few lines or tail to see the last few.
Example 1: View the first 5 orders.
head -6 sales_data.csv
Example 2: View just the column headers.
head -1 sales_data.csv
Example 3: View the last 5 orders.
tail -5 sales_data.csv
Example 4: Skip the header and see the data
tail -n +2 sales_data.csv | head -3
9. find – Locate Files Across Directories
When working on projects, you often need to find files scattered across directories, and the find command is incredibly powerful for this.
First, let’s create a realistic directory structure:
mkdir -p data_project/{raw,processed,reports}
cp sales_data.csv data_project/raw/
cp sales_data.csv data_project/processed/sales_cleaned.csv
echo "Summary report" > data_project/reports/summary.txt
Example 1: Find all CSV files.
find data_project -name "*.csv"
Example 2: Find files modified in the last minute.
find data_project -name "*.csv" -mmin -1
Example 3: Find and count lines in all CSV files.
find data_project -name "*.csv" -exec wc -l {} ;
Example 4: Find files larger than 1KB.
find data_project -type f -size +1k
10. jq – JSON Processor Extraordinaire
In modern data science, a lot of information comes from APIs, which usually send data in JSON format, a structured way of organizing information.
While tools like grep, awk, and sed are great for searching and manipulating plain text, jq is built specifically for handling JSON data.
sudo apt install jq # Ubuntu/Debian sudo yum install jq # CentOS/RHEL
Let’s convert some of our data to JSON format first:
cat > sales_sample.json << 'EOF'
{
"orders": [
{
"order_id": 1001,
"customer": "John Smith",
"product": "Laptop",
"price": 899.99,
"region": "North",
"status": "completed"
},
{
"order_id": 1002,
"customer": "Sarah Johnson",
"product": "Mouse",
"price": 24.99,
"region": "South",
"status": "completed"
},
{
"order_id": 1006,
"customer": "Sarah Johnson",
"product": "Laptop",
"price": 899.99,
"region": "South",
"status": "pending"
}
]
}
EOF
Example 1: Pretty-print JSON.
jq '.' sales_sample.json
Example 2: Extract all customer names.
jq '.orders[].customer' sales_sample.json
Example 3: Filter orders over $100.
jq '.orders[] | select(.price > 100)' sales_sample.json
Example 4: Convert to CSV format.
jq -r '.orders[] | [.order_id, .customer, .product, .price] | @csv' sales_sample.json
Bonus: Combining Tools with Pipes
Here’s where the magic really happens: you can chain these tools together using pipes (|) to create powerful data processing pipelines.
Example 1: Find the 10 most common words in a text file:
cat article.txt | tr '[:upper:]' '[:lower:]' | tr -s ' ' 'n' | sort | uniq -c | sort -rn | head -10
Example 2: Analyze web server logs:
cat access.log | awk '{print $1}' | sort | uniq -c | sort -rn | head -20
Example 3: Quick data exploration:
cut -d',' -f3 sales.csv | tail -n +2 | sort -n | uniq -c
Practical Workflow Example
Let me show you how these tools work together in a real scenario. Imagine you have a large CSV file with sales data, and you want to:
- Remove the header.
- Extract the product name and price columns.
- Find the top 10 most expensive products.
Here’s the one-liner:
tail -n +2 sales.csv | cut -d',' -f2,5 | sort -t',' -k2 -rn | head -10
Breaking it down:
tail -n +2: Skip the header row.cut -d',' -f2,5: Extract columns 2 and 5.sort -t',' -k2 -rn: Sort by second field, numerically, reverse order.head -10: Show top 10 results.
Conclusion
These 10 command-line tools are like having a Swiss Army knife for data. They’re fast, efficient, and once you get comfortable with them, you’ll find yourself reaching for them constantly, even when you’re working on Python projects.
Start with the basics: head, tail, wc, and grep. Once those feel natural, add cut, sort, and uniq to your arsenal. Finally, level up with awk, sed, and jq.
Remember, you don’t need to memorize everything. Keep this guide bookmarked, and refer back to it when you need a specific tool. Over time, these commands will become second nature.